딥러닝: 퍼셉트론
퍼셉트론은 현대 신경망의 가장 원시적인 형태의 모델이다. 우리가 흔히 이야기하는 딥러닝을 포함한 신경망은 퍼셉트론을 병렬 혹은 순차적으로 결합한 형태에 불과하다. 그렇기 때문에 퍼셉트론에 대한 특성을 공부해야할 필요가 있다. 총 두차례에 걸쳐 퍼셉트론에 대한 전반적인 내용을 다루고자 한다. 이번 포스트에서는 아래와 같은 내용을 다룬다.
- 퍼셉트론의 구조
- 퍼셉트론의 동작
- 퍼셉트론의 학습
- 퍼셉트론의 한계
이후 다음 포스트에는 퍼셉트론의 한계로 인해 등장한 다중 퍼셉트론에 대한 내용을 다루고자한다. 행렬의 내적과 코사인 유사도(Cosine similarity) 및 목적함수(Loss function)에 대한 개념을 알고 있다는 가정하에 진행되므로 잘 기억이 안난다면 리마인드하고 읽는 것을 추천한다. 이제 퍼셉트론에 대해 본격적으로 알아보도록 하자.
퍼셉트론의 구조와 동작
우선 다음 아래의 그림부터 보자.
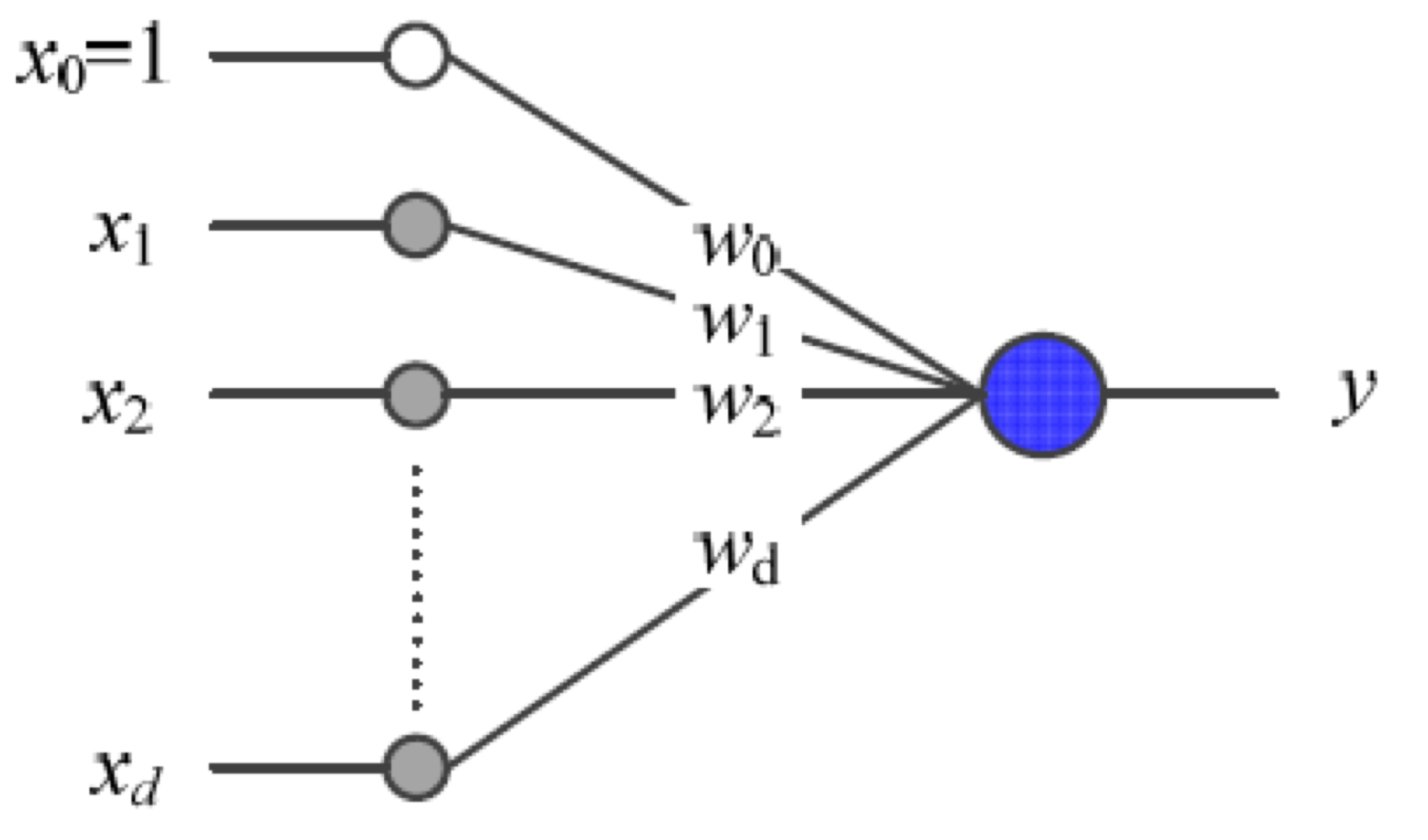

그림에서 동그라미에 해당하는 것을 노드(node)라고 부른다. 어떠한 값을 담고 있으며 이 값은 가중치(weights)라고 하는 값과 곱해진다. 왼쪽의 노드들을 묶어서 입력층(input layer)이라고 부르고 오른쪽의 파란 노드를 출력층(output layer)이라고 한다. 그럼 입력층의 노드들을 보자. $x_i$는 $i$번째에 해당하는 입력이다. 예를 들어, 꽃잎의 길이, 꽃받침의 넓이, 꽃받침의 길이, 꽃잎의 넓이 총 4개의 특성을 이용하여 꽃의 종류를 예측하는 퍼셉트론을 구성한다고 해보자. 그럼 $d$는 4이고 $x$는 각각의 특성에 해당하는 값을 나타낸다. 그런데 왜 $d+1$개의 노드들이 있는 것일까? $x_0$는 값이 1로 고정되어있는 노드인데 편향(bias)이라고 하는 값을 표현하기 위한 편향 노드(bias node)이다. 편향은 단순 상수로 $b$로 표현하기도 한다. 선형 회귀에서 $Wx+b$의 $b$와 동일한 개념이다. 다음 아래의 수식을 보면 조금더 명확하게 이해할 것이다.
$$ \sum ^d_{i=0}x_i\cdot w_i = \sum ^d_{i=1}(x_i\cdot w_i) + b ,\; where\; w_0=b $$
출력층의 노드에서는 가중치와 곱해진 값들이 모두 더해지고 활성화 함수 $\tau$가 적용된다. 퍼셉트론에서는 활성화 함수를 오른쪽 그림과 같은 계단함수로 사용한다. 따라서 출력값 $y$에 대해 다음 아래의 식으로 나타낸다.
$$ a=\sum ^d_{i=0}x_i\cdot w_i \\ y=\tau (a), \tau(a) = \begin{cases}1 & a >= 0 \\ -1 & a < 0 \end{cases} $$
위 식을 행렬로 표현하면 조금더 쉽게 표현할 수 있는데,
$$a=\mathbf{w}^T\mathbf{x},\;where\; \mathbf{x}=(x_0,\cdots,x_d)^T,\,\mathbf{w}=(w_0,\cdots,w_d)^T $$
로 표현할 수 있고 앞으로 신경망이 복잡해질수록 행렬로 표기하는 것이 훨씬 쉬워진다.
계단 함수를 기하학적으로도 해석할 수 있는데 단순하게 선형적으로 분류하는 역할을 한다. 단순히 입력 공간을 2차원으로 가정해보자. 그럼 아래 그림과 같이 2차원 평면에 $(x_1,\cdots,x_4)$와 같이 데이터를 표현할 수 있다.

만약 $\mathbf{w}=(1,1,-0.5)^T$라면, $a=x_1+x_2-0.5$이고 계단함수를 통해 출력이 1과 -1로 나누어질 수 있다. 이렇게 퍼셉트론은 데이터를 선형적으로 분리하는 분류 모델로 작용한다. 예시와 같이 2차원인 경우 결정 직선이라고 하고 3차원에선 결정 평면, 4차원 이상에서는 결정 초평면이라고 부른다.
퍼셉트론의 학습
이전 최적화를 소개하는 포스트에서 목적함수에 대한 내용을 다루었다. 혹시 목적함수에 대한 내용을 잘 모른다면 여기에서 보고 오면 이해하기 좋을 것이다. 중요한 부분만 언급하면 목적함수는 양수이고 출력값이 실제 값보다 많을 수록 증가하는 특성을 보이는 함수이다. 그럼 퍼셉트론에서는 어떤 목적함수를 사용하여 학습에 이용할까?
$$ J(\mathbf{w})=\sum_{\mathbf{x}_k\in Y}-y_k(\mathbf{w}^T\mathbf{x}_k) $$
$Y$는 틀린 샘플의 집합이다. 즉, 틀린 샘플에 대해서 실제값과 활성화 함수가 적용되지 않은 출력과 곱의 합을 의미한다. 이제 가중치 갱신 규칙인 $\theta = \theta - \rho g$를 적용하여 가중치를 갱신한다. $\mathbf{w}$에 대해 목적함수를 미분해야하므로
$$ \frac{\partial J(\mathbf{w})}{\partial w_i}=\sum_{\mathbf{x}_k\in Y}{\partial (-y_k(w_0x_{k0}+ \cdots + w_dx_{kd}))\over \partial w_i} = \sum_{\mathbf{x}_k\in Y}-y_kx_{ki} $$
이제 각 가중치에 대한 미분을 구했으므로 이를 이용하면
$$ \begin{align} w_i &= w_i - \rho {\partial J(\mathbf{w})\over \partial w_i} \\ &= w_i + \rho \sum_{\mathbf{x}_k\in Y} y_kx_{ki} \end{align}$$
이다. 이때 $\rho$는 학습률(learning rate)로 지정해줘야하는 파라미터 중 하나이다. 이렇게 퍼셉트론을 학습시키는 규칙을 델타 규칙(delta rule)이라고 한다.
이 델타 규칙의 메커니즘을 조금 더 살펴보면 유사도가 높은 입력에 대해 가중치를 증가하는 특성이 있는 것을 확인 할 수 있다. 정확하게 이야기하자면 틀린 샘플에서 실제값($\mathbf{y}$)과 입력($\mathbf{x}$)의 내적값이 높다면 가중치가 증가한다.
예를 들어, 입력이 $\mathbf{x} = \begin{pmatrix} 1 & -1 & 1 \\ -1 & 1 & 1 \\ 1 & -1 & -1 \\ -1 & 1 & -1 \end{pmatrix}$이고 실제 값이 $\mathbf{y} =\begin{pmatrix} 1 \\ -1 \\ 1 \\ -1 \end{pmatrix} $인 예측이 틀린 샘플 데이터가 있다고 하자(편의상 편향은 무시한다). 첫번째 입력에 대해
$$\begin{align}w_1&=w_1+\rho \begin{pmatrix} 1 & -1 & 1 & -1 \end{pmatrix} \cdot \begin{pmatrix} 1 \\ -1 \\ 1 \\ -1 \end{pmatrix} \\ &= w_1 + 4*\rho \end{align}$$
이다. 반면 3번째 입력에 대해
$$\begin{align}w_3&=w_3+\rho \begin{pmatrix} 1 & -1 & 1 & -1 \end{pmatrix} \cdot \begin{pmatrix} 1 \\ 1 \\ -1 \\ -1 \end{pmatrix} \\ &= w_3 + 0*\rho \end{align}$$
이다. 이러한 특성을 고려하여 목적함수를 설계한 것은 아니겠지만 목적함수를 사용함에 있어서 유사도가 높은 입력에 더 높은 가중치를 부여하는 의미는 그럴듯 하게 보인다.
퍼셉트론의 한계
1969년 민스키(Minsky)와 페퍼트(Papert)는 Perceptrons라른 저서에서 퍼셉트론의 한계를 수학적으로 입증하여 퍼셉트론의 한계를 증명하였다. 퍼셉트론은 단순 선형 분류기에 불과하여 복잡한 문제를 해결하지 못한다는 내용이다. 한 예로 여러분은 아래의 검은색과 하얀색 점들을 하나의 직선으로 분리할 수 있는가?

결코 하나의 직선만으로는 이 둘을 분리할 수 없다. 퍼셉트론은 근본적으로 선형분리가 가능한 문제에 대해서만 처리가 가능하다는 치명적인 단점이 있다. 이러한 문제로 1970년대에 신경망 연구의 암흑기가 오게 되었다. 이후 1974년 발표된 오류역전파 알고리즘이 제안되었고 1986년 Parallel Distributed Processing: Exploarations in the Microstructure of Cognition에서 다층 퍼셉트론의 개념이 등장하면서 신경망이 부활되었다.
지금까지 퍼셉트론의 구조와 동작원리 및 한계를 알아보았다. 퍼셉트론은 한계점이 너무나 명확한 모델이기 때문에 복잡한 현대사회의 문제를 풀기에 적합한 모델은 아니다. 하지만 이 개념이 발전하여 다층 퍼셉트론, 딥러닝 등이 등장했기 때문에 꼭 알아둬야할 모델이다. 다음 시간에는 더 발전된 다층 퍼셉트론에 대해 알아보자.
이 포스트는 "기계 학습(오일석 지음)"을 바탕으로 작성되었습니다.